Hi Guys, this discussion is about Big data and how it’s changing the way we look at data.We will discuss few tools available in AWS cloud for processing Big data.
- Redshift Databases
- Data processing with EMR(Elastic Mapreduce)
- Streaming data with Kinesis
- AWS Athena and AWS Glue
- Quicksight
- Elasticsearch
What is Big data : There are 3 main parts that make up Big data
- Volume : The word itself gives it away , Big data is huge of amount of data ranging from Terabytes to Petabytes of data.
- Variety : The data comes from a wide range of sources and formats.
- Velocity : If you think that you have so much data but you are unable to process the data in quick time , then the data is of no use. We need to be able to collect data from a variety of sources and be able to process in very quick time.
Redshift
Redshift is fully managed , petabyte -scale data warehouse service in the cloud . But if you think of it, it’s a very large relational database but which is traditionally used in big data applications.
- Redshift can be used to store massive amount of data . It can store upto 16 PB of data which means you do not have to split up your datasets.
- The database is relational and we can use the standard SQL and Business intelligence(BI) tools to interact with it.
- But be careful , the main use case of Redshift of BI applications and it’s not a replacement of standard RDS databases.
- Redshift only supports single-AZ deployments.
Elastic Mapreduce
Before we discuss EMR we need to know what is ETL which means Extract , Transform and Load . So what that means is that first process is the collection of Raw data from variety of sources which is then transformed into usable form .
EMR : AWS EMR is ETL service which is a managed big data platform that allows you to process vast amounts of data using open-source tools such as Spark , Hive etc.
Its an Open source cluster. The way it works is that the EMR service will spin up EC2 instances and install the software on them which is chosen by you when you setup your cluster.The cluster will always reside in our VPC and then save the processed data on S3.
Kinesis
Kinesis allows you to ingest , process, and analyse real-time streaming data. It’s like a pipeline of data which is used to transport data from point A to B.
There are two versions of Kinesis:
- Data Streams: This is mainly used for real-time streaming for ingesting data. The only point to note is that you will be responsible for creating the consumer and scaling the stream which can be a lot of work.

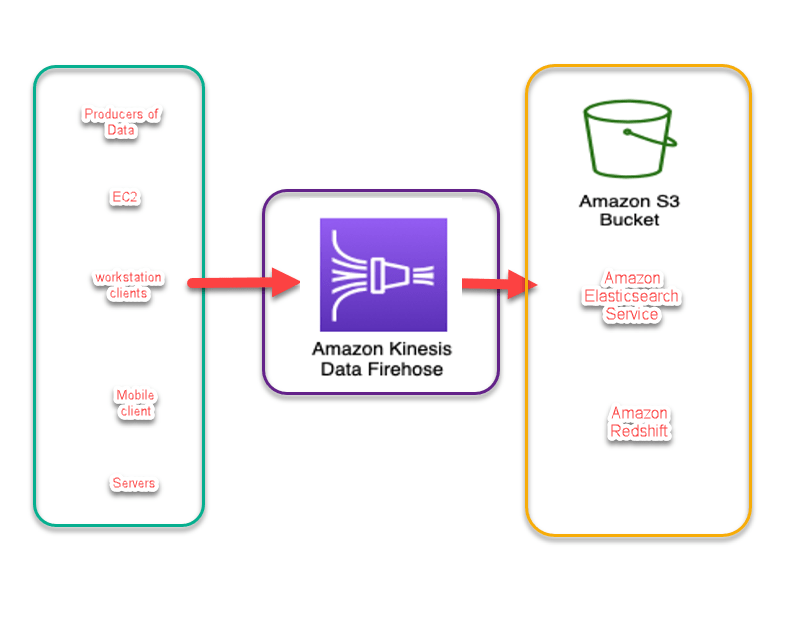
Data Firehose
Data Firehose is much simpler. It will handle building the consumer that you had to do in Amazon Kinesis . This is a managed service from AWS which was released after learning lessons from AWS kinesis. The data that is saved to the end points is limited to few services namely Amazon Elasticsearch service , Amazon S3 and Amazon Redshift . It does the same thing as Kinesis Data streams but its lot simpler .
Kinesis Data Analytics
Kinesis Data streams or Firehose is not going to process that information as its a streaming service which delivers data from point A to B .But we you want to analyse the data , that is where Kinesis Data Analytics comes into picture where you can combine Kinesis Data streams or Firehose in combination with Kinesis Data Analytics to process our information using standard SQL.
- Its very simple to tie Data Analytics into your Kinesis Pipeline. Its directly supported by Data Firehose and Data Streams.
- There is no servers to manage to use this service as its a fully managed real-time serverless service.It will automatically handle scaling and provisioning of needed resources.
- You only pay for the amount of resources you consume as the data passes through.
AWS Athena and AWS Glue
Athena is an interactive query service that makes it easy to analyse data in S3 using SQL. This allows you to directly query data in your S3 bucket without loading the data into Database.
AWS Glue is a serverless data integration service that makes it easy to discover , prepare and combine data. It allows you to perform ETL workloads without managing underlying servers.
So basically with this service you can replace EMR which spins up EC2 instances to extract , transform and load the data without the EC2 .
We can combine these two solutions: We need to point the our AWS glue crawlers to unstructured data in S3 , AWS Glue will make a data catalog which can then be combined with AWS Athena to run queries on that catalog . Both Athena and Glue are serverless services.
Quicksight
Amazon Quicksight is a fully managed business intelligence (BI) data visualization service. It allows you to easily create dashboards and share them within your company. In the last topic we discussed the flow where data is cataloged from S3 by AWS glue , after which we use AWS Athena to query that data and Quicksight frontends this whole solution by making dashboards out of that queried data.

Elasticsearch
Amazon Elasticsearch Service is a fully managed version of the open source application Elasticsearch. It allows you to quickly search over your stored data and analyse the data you get back. It’s commonly used as part of an Elasticsearch, logstash, kibana(ELK) stack. It’s mostly used for analysing logs where you can send your logs to Elasticsearch and get the data out which you can analyse.

Leave a comment